





Nvidia researchers have published a paper describing a rendering framework that can produce 3D objects from 2D images. Not only that, due to the power of machine learning and AI, the tech does a good job of predicting the correct shape, colour, texture and lighting of the real-life 3D objects. The research could have important impacts in machine vision with depth perception, for robotics, self driving cars, and more.
The full research paper, typically dryly entitled Learning to Predict 3D Objects with an Interpolation-Based Renderer, is available as a PDF by clicking the link. A new rendering framework called DIB-R, a differentiable interpolation-based renderer, is the main topic of the paper. DIB-R is claimed to be a high-fidelity renderer using an encoder-decoder architecture. The renderer uses a neural network that transforms 2D input imagery into a feature map or vector that is used to predict specific information of the real-world object.
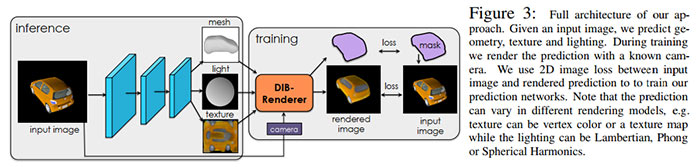
As one might imagine, DIB-R will be particularly attractive in fields like robotics where an autonomous robot can predict and plan routes and interactions within an environment. DIB-R can transform 2D images into 3D portrayals of objects it has learned about in under a second.
In some background information about the Ai renderer, Nvidia says that DIB-R is built on PyTorch, a machine learning framework, and it is provided as part of Kaolin, a 3D deep learning PyTorch library. In the research paper documented tests DIB-R was trained for two days using various data sets and a single Nvidia V100 GPU based system.

In the bird example, shown above, after training the DIB-R could take an image of a bird and produce a 3D portrayal with the proper shape and texture of a 3D bird in <100 milliseconds.
"This is essentially the first time ever that you can take just about any 2D image and predict relevant 3D properties," summarised Jun Gao, one of a team of researchers who collaborated on DIB-R.







