





Last week's reveal of the Apple M1 SoC for Mac computers was surely a significant moment in computing history. The launch event which saw three new Macs launched, powered by this 5nm Arm-based processor, was full of the typical Apple bombast but unfortunately the astonishing performance claims and comparisons weren't fleshed out with proper hardware reference points. Put simply we didn't really know the basis of Apple's claims for things like 'up to 3.5x faster CPU', even after pondering over the small print.

Ahead of launch we saw some Geekbench results which were rather exciting for Mac fans but this benchmark seems more suited to mobile platforms. Thus, when Maxon launched its M1 code native Cinebench R23 a day or two after the Apple event, I had some hope that folk who received their new Macs over the weekend would run the pro rendering benchmark in single and multi-core mode to provide a better PC processing comparison.

A few hours ago Italian tech site Bits And Chips revealed one of the first Cinebench R23 scores from an Apple Mac packing an M1 SoC. It shared the result alongside runs undertaken on the AMD Ryzen 5 3600X desktop CPU (95W). It was called out for the apples and oranges comparison so then added a run from a Ryzen 7 4800HS mobile processor (35W). I've put all three CB23 results in a table below:
|
Cinebench R23 test |
Apple M1 |
AMD Ryzen 5 3600X |
AMD Ryzen 7 4800HS |
|
Single thread |
990 |
1,300 |
1,230 |
|
Multi-thread |
4,530 |
9,500 |
10,600 |
I must comment that the little Apple M1 is a close competitor to my Dell XPS 15 laptop's Intel Core i5-8300H (45W) processor.which scores single/multi 1,038/4,284 points in the new Cinebench R23.
With the Apple M1 Cinebench R23 results thought to be in the bag and in line with the above, one might argue that these first Apple Macs aren't designed for pro rending apps like Maxon Cinema 4D. Perhaps a better choice would be a photo/vector art application – a lighter weight creative app category which is probably more popular for publishers / web designers and the like.

Shortly after the M1 Macs were launched Andy Somerfield of Serif Software in the UK, makers of the popular Affinity creative productivity apps, shared an interesting set of results from the Affinity Photo built-in CPU and GPU benchmark.
Somerfield was quite taken aback by how well the Apple M1 chip performed in this vector/raster creation and manipulation app, calling the new M1 "a monster". He compared his M1 Mac against an iMac with 9th gen 6-core 3.7GHz Intel CPU (i5-9600K, according to EveryMac) and AMD Radeon 580X GPU. I've put the comparative benchmark results tables side by side below (click to zoom).
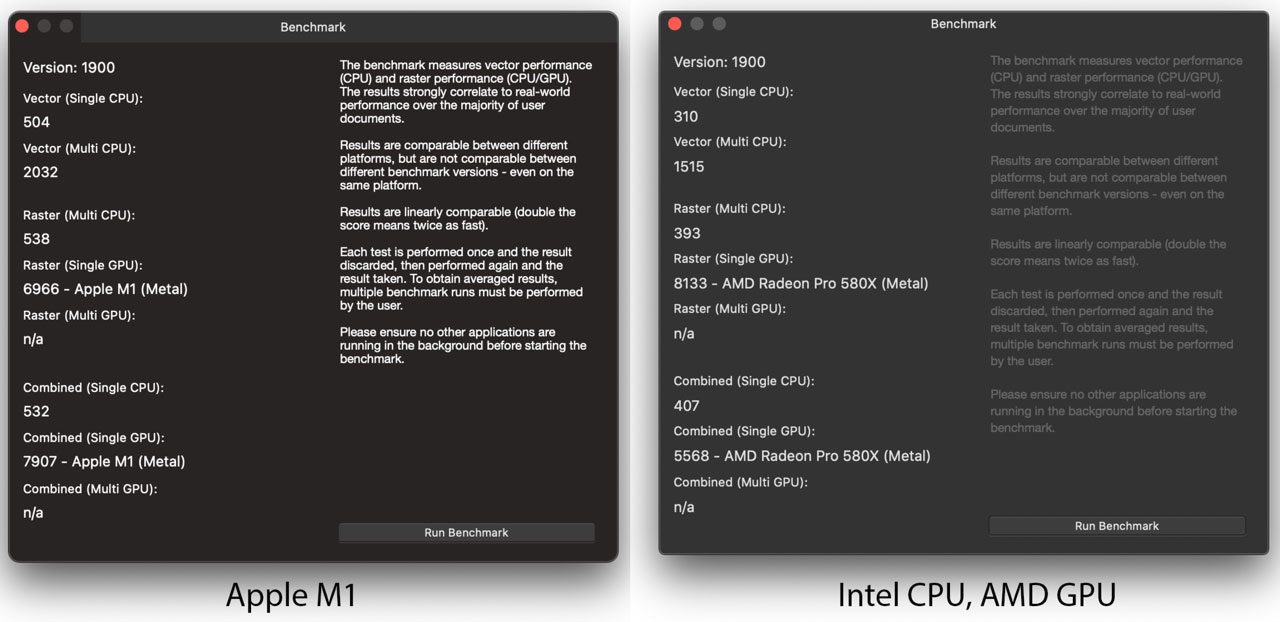
Update:
It looks like the Bits and Chips CInebench R23 result is not for the Apple M1 SoC but from an A12Z. MacRumours has a result in that it reckons is from a genuine new M1 13-inch MacBook Pro, though, and it is somewhat better than the A12Z, of course. It quotes Twitter user @mnloona48_ who shared an MBP M1 unboxing and various other tests on his new 8GB machine. Mnloona48's Cinebench R23 scores are an impressive 1,498 single core, 7,508 multi core. Thanks to Mr Williams for the heads up.







