





Set to a backdrop of industry-standard APIs such as Microsoft's DirectX, GPUs have been transformed from fixed-function compute units to increasingly programmable models, where developers can tap into the ultra-wide architectures as they best see fit.
Modern GPUs leverage the fact that rasterisation - the process by which pixels are painted on your screen - is inherently parallelisable: you chuck data streams down a number of pipes - and the more, the better - wait a while, and then post-process.
This make-it-as-wide-as-possible approach, together with a flexible, programmable architecture, makes NVIDIA's G80/9x and ATI's R(V)6xx thoroughbred GPUs with masses of potential throughput, hiding latency via sheer concurrent computation.
Thinking about the throughput, as defined by the basic building-block that is the multiply-add rate, and therefore taking the floating-point performance into account, ATI's Radeon HD 3870 X2, released last month, can hit around 1TFLOPS (one trillion floating-point operations per second). Its 320 stream processors combine for massive parallel computation. Further, relatively massive bandwidth keeps the stream processors chugging along with data, too.
In contrast, though, a high-end quad-core CPU can push out around 60GFLOPS, or one-sixteenth the amount of floating-point power.
Now, pure floating-point power is only one metric in evaluating overall performance of a particular kind of processor, but as a means of a finger-in-the-air evaluation at just how good a particular SKU will be with respect to parallelisable workloads, mainly scientific-based, the FLOPS rating suffices.
These GPU FLOPS monsters are powerful enough to run more than just gaming code at high resolutions and high degrees of image quality. Given the right kind of workload, which is inherently and ostensibly parallelisable, they can be programmed such that performance is significantly better than, say, running the same dataset on the CPU.
Game developers cite examples such as complex physics calculations and cinema-quality effects, but there is now a nascent industry which seeks to leverage floating-point power for non-graphical purposes. You may know this as GPGPU.
GPGPU (General Purpose (computation) on Graphics Processing Units) looks at a myriad of non-graphic-related tasks and evaluates how they can, if possible, be run faster on GPUs.
Big Business exploits GPU power by utilising them in complex calculations for oil and gas exploration; medical imaging; weather analysis; general computationally-heavy research; and complex engineering modelling, to name but a few.
Writing efficient, tight code for high-performance discrete GPUs - which, remember, are from either NVIDIA or ATI - requires access to the inner workings of the architecture and, really, an easy-to-program language and abstraction layer which translates code into GPU-talk. Big Business can afford to commission its own libraries and third-party tools, though. Big Business can also afford to buy the FireStream 9170 Stream Processor, pictured below. Note that there's no reference to it being based almost exclusively on the Radeon HD 3870 graphics card, albeit with a larger frame-buffer and 10x price.

AMD disclosed that its Stream Computing initiative - the term for programming non-gaming-related code on GPUs - will make it easier for Joe Bloggs (with a big brain) to get to the heart of its GPUs and code for GPGPU use by providing a range of open-source compilers (Brook+), and libraries - gratis. These fall under the FireStream SDK (Software Development Kit) that's gives the developer low-level access to the workings of the GPU, allowing for granular control, and the tools by which to program. If you know what you're doing, and plenty of bright sparks at scientific institutions and universities do, you can write your own code for ATI cards.
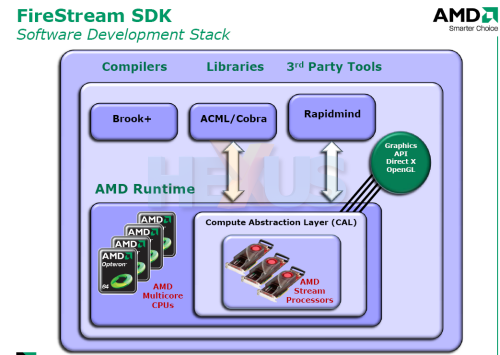
Understanding that the research community may well take advantage of the floating-point power on offer and writing code is now made easier as access it 'closer to the metal', how does it help you, the average consumer?
As it happens, many media-rich applications' code is wonderfully parallelisable, meaning that, if coded for, additional plug-ins could take the load off the CPU, place it on the broad, broad shoulders of the GPU, and execute in a more-timely fashion. As an example, during the CTO conference in Amsterdam, Holland, a high-definition clip was transcoded to MPEG2 HD. Running on a Radeon HD 3870 X2, with the Adobe Premier plug-in activated, the GPU ran at 4x a quad-core CPU's speed.
Now, it's clear that extensive developer-relations' support needs to be fostered and promoted before large software houses bother to take advantage of the GPU's massive horsepower, but we see GPGPU as more than just a fad. Rather, the burgeoning industry needs to be helped along via close collaboration with NVIDIA and AMD.
Transcoding HD material or delving into areas such as voice-recognition is still a time-consuming affair and any attempts to leverage the GPU for such tasks is nothing but sensible practice. It opens up the door for AMD to sell FireStream-branded cards at a wonderful premium, too.
After talking to Mike Houston, senior software architect for AMD's Stream Computing initiative, ATI had consciously designed present and upcoming GPUs with GPGPU usage firmly in mind. The Radeon HD 3870 is outfitted with double-precision floating-point accuracy - a feature that's not required when executing gaming code. Rather, it's useful in mission-critical instances where computational accuracy outweighs pure speed.
So the next time you look at the Radeon HD 3870 or NVIDIA GeForce 8800 GT in your machine, remember that it's more than just a graphics card; it's a floating-point monster that will increasingly be used for non-graphical tasks. We will see media-rich applications harness the TFLOPS on offer, so any initiative made to expedite and facilitate that process can only be seen as a good thing.
TeraFLOPs, who needs 'em? The answer is everyone. Bear that in mind when transcoding a two-hour HD feed or running Folding@Home.







