





Introduction

After labouring with practically no presence in the x86 server market for a long time, AMD has built momentum through the release of Zen-based Epyc processors starting with first-generation 'Naples' in 2017.
AMD took advantage of Intel roadmap slips by releasing second-generation 'Rome' in 2019, which is particularly notable for doubling the core-and-thread count and quadrupling the L3 cache in one generation and on the same underlying platform.
The capability of AMD's server hardware has since convinced the leading server vendors - Dell, HPE, Lenovo, et al - to take Epyc seriously, and each has product lines for a broad range of use-cases.
Latest figures suggest that AMD is homing in on 10 per cent market share, from a standing start four years ago, and aiming to solidify the server proposition is third-generation Epyc chips codenamed Milan.
Known officially as Epyc 7003 Series, AMD is releasing 19 processors that span from eight to 64 cores in various SMT-enabled implementations. Compatible with existing Rome-certified SP3 motherboards through a BIOS update, AMD wants to make the possible transition as easy as possible, all the while tempting new users into the high-performance fold.
We have the range-topping 64C128T Epyc 7763 in for review today in dual-processor form, but before we get to the benchmarks, it is instructive to take a look at what improvements AMD has made from the last generation released in August 2019.
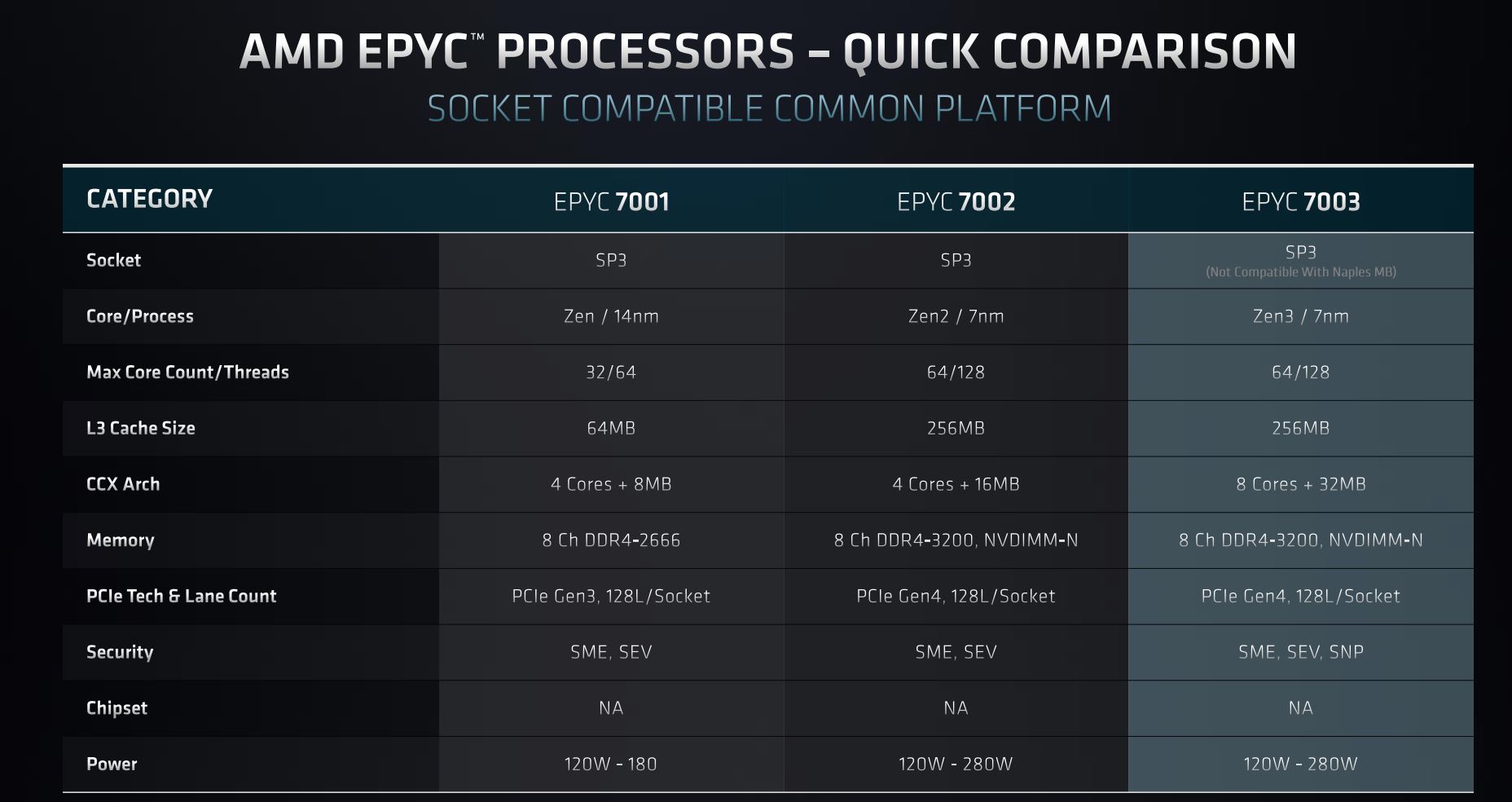
Starting from high-level details and drilling down as we go, let's make it abundantly clear that customers are not going to see the same generation-to-generation jump as from Epyc 7001 Series (Naples) to Epyc 7002 Series (Rome).
The simple reason is the highest core-and-thread count remains unchanged. 64 cores and 128 threads continue to be class-leading for dual-socket-capable x86 server chips, but the simple truth is the present 7nm process doesn't allow for significantly more cores without chip power rising to untenable levels. Expect the next generation to implement a process shrink and fit even more cores.
Taking a further peek down the two right-hand columns reveals many similarities, so it's easier to explain the changes AMD has made this generation.
Pure performance gains are availed through a two-prong process which accumulates the benefits of a newer, better architecture alongside the advantage of higher frequencies. This strategy is reminiscent of the desktop overhaul to Ryzen 5000 Series, which makes sense as the underlying Zen architecture is tightly aligned to manufacturing process.
Zen 3, therefore, makes its long-awaited debut on server, and if desktop is anything to go by, the work done per clock cycle increases by around 20 per cent, measured across a broad swathe of applications. We'll explain more just below.
Other than that, notable callouts include a Zen 3-induced redesign of the caching structure, leading to lower-latency access able to fit double-sized datasets straight into unified L3, the ability to interleave six memory channels for eclectic implementations, and a more robust security feature-set.

Zen 3's chief improvements include a more efficient branch predictor that's able to get instructions into the machine sooner (larger BTB buffer) and therefore executed faster (better predictor bandwidth). AMD says it now has technology to eliminate the pipeline bubbles that normally exist when alternating between input instructions. Mispredicts can be flushed more quickly, too, and Zen 3 is able to load regular and op-cache instructions faster, which is of particular benefit on server-type workloads.
On the execution front and compared to Zen 2, there's now an extra branch unit and store data pickers. You'll notice that the floating-point unit can now accommodate a six-wide dispatch, up from four. Of particular interest to Epyc is AMD's decision to double the INT8 pipes and rate, representing faster low-precision CPU-side inferencing commonly used in deep learning and AI in general.
AMD refers to Zen 3 as a grounds-up design but it feels more like a collection of sensible tweaks combining to offer better IPC. The architecture is smarter, more efficient and able to extract more performance without adding to energy consumption - a win-win in practically all situations. Anything over a 15 per cent IPC improvement is considered reasonable for an x86 generational uplift.

Outside of pure IPC improvements availed through architecture enhancements, Milan introduces a six-channel memory option on top of the 4/8-channel available on Rome. Designed to address the low-to-mid-core section of the market that needs extra memory flexibility and wants to build very purpose-specific servers, it's not a feature that can be backported to second-generation Rome; the central I/O die is materially different to accommodate it.
Another reason for the I/O die being marginally different rests with upgrades to the Secure Processor, handling, as the name suggests, security through cryptography. Milan carries additional Secure Nested Paging (SNP) capability which protects RAM from malicious hypervisor attacks such as memory and data remapping.



